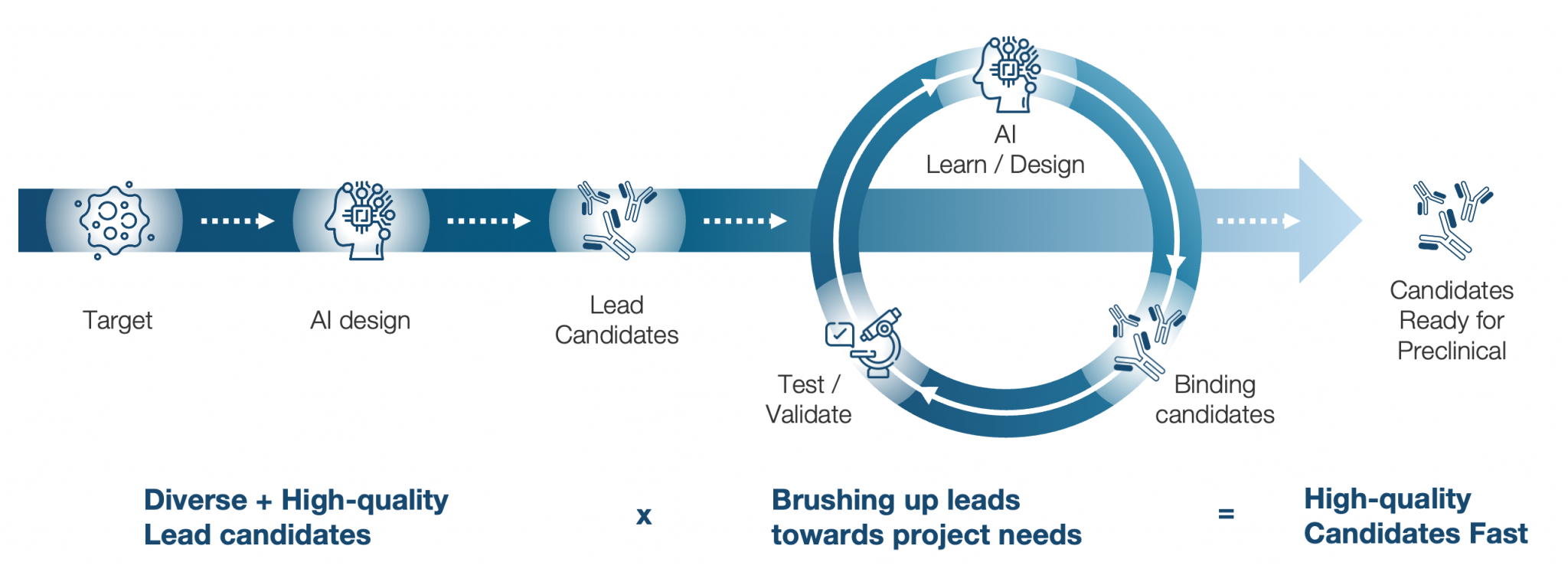
MOLCURE's AI platform
Enhancing the end-to-end drug discovery process through AI integration
de novo Discovery AI
Lead Optimization AI
Wide Range of AI Application
Our sequence-based ML model is applicable to multiple modalities of drugs.

Antibody

Aptamer
Peptide
CAR-T

Bispecific
Showcase: VHH antibody discovery project against RBD protein (SARS-CoV-2)
Explore how MOLCURE’s AI platform performed true de novo discovery, generating novel, high-affinity VHH antibodies against SARS-CoV-2 RBD without relying on any prior antibody knowledge for the target. Our AI designed diverse candidates with accurately predicted picomolar to nanomolar affinities and broad epitope coverage, achieving an impressive 83% sub-micromolar hit rate from generated sequences. Validated through strong correlation with experimental data and independent epitope mapping, this showcases our AI’s proven capability to rapidly identify diverse, high-quality therapeutic candidates.
Workflow
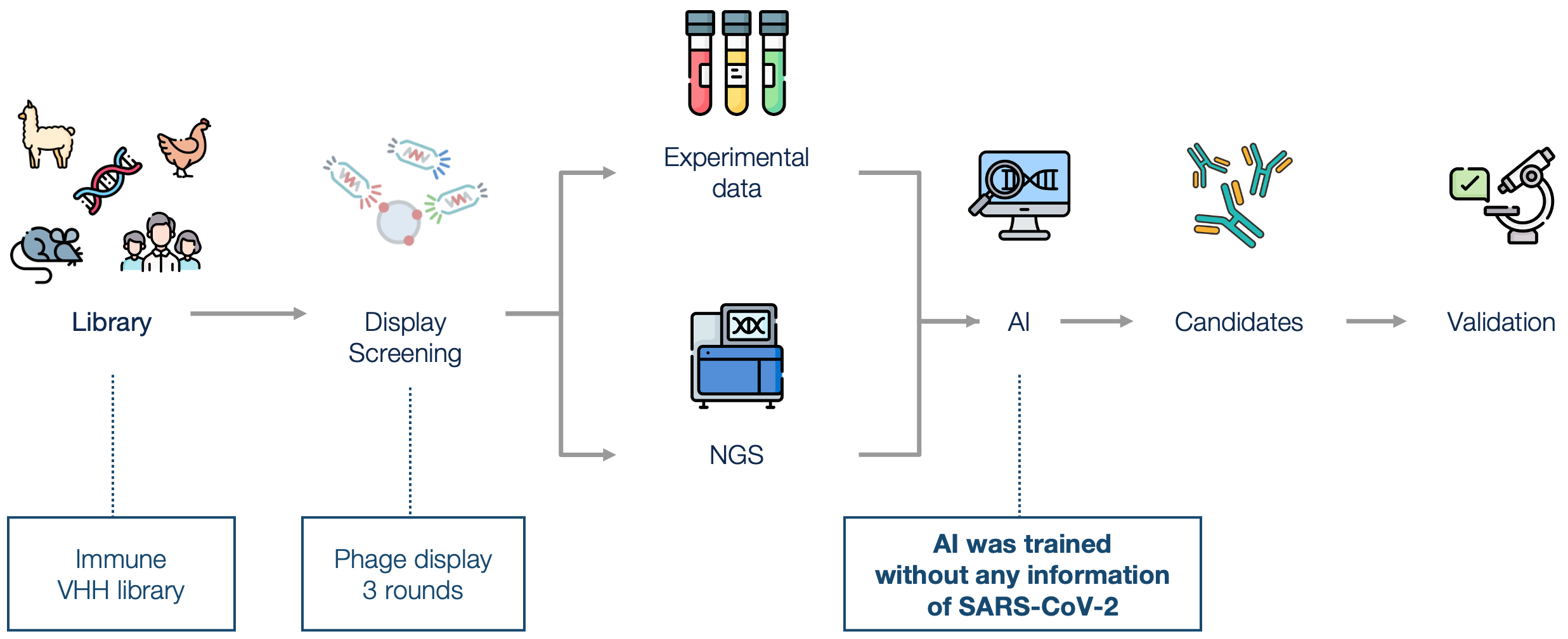
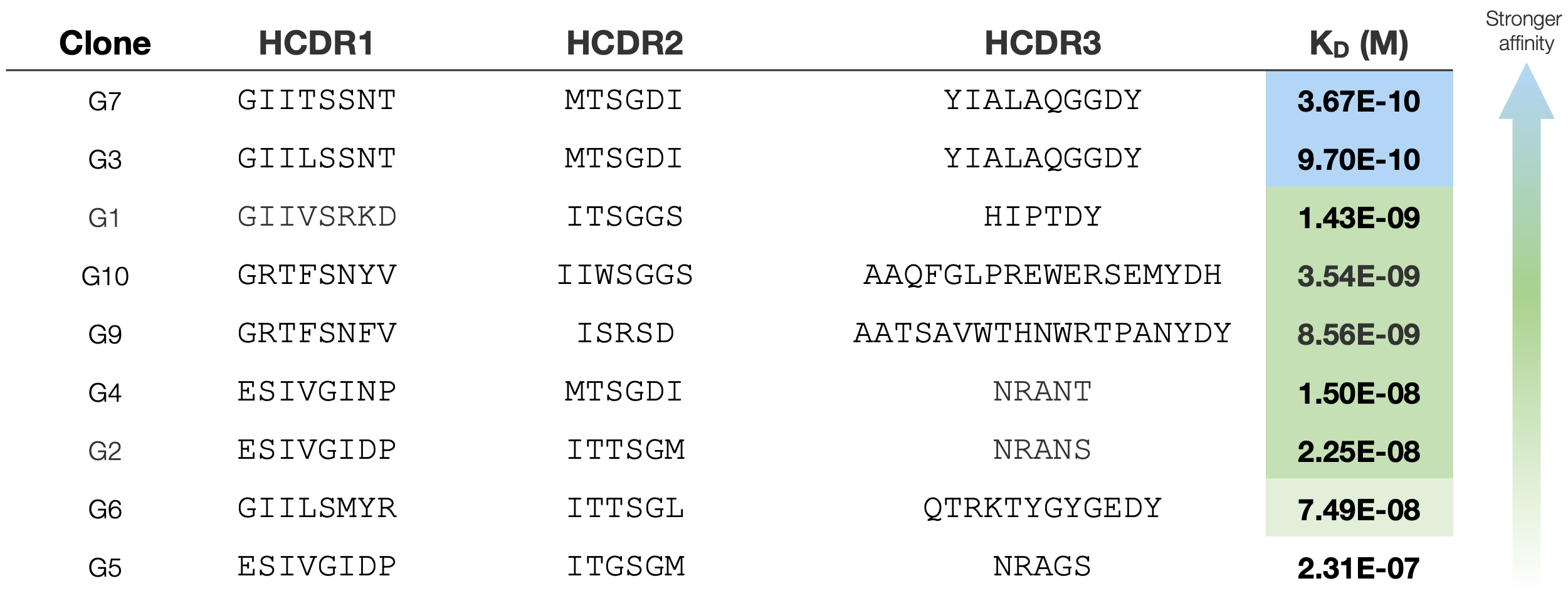
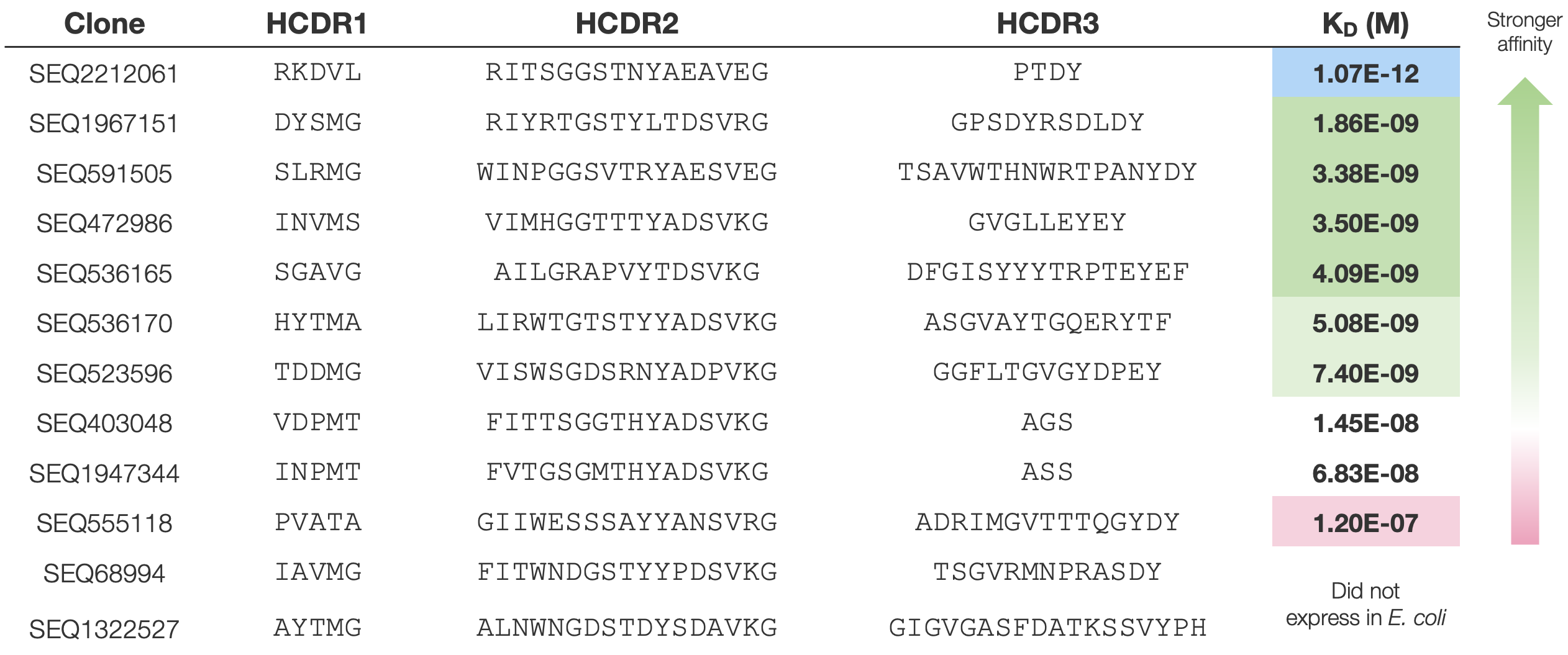
Result: Candidates with strong affinity
MOLCURE’s AI generated diverse antibody candidates demonstrating high affinity, with 83% achieving sub-micromolar binding based on experimental measurements and top candidates reaching picomolar levels. This high hit rate underscores the AI’s robust predictive power for binding affinity, significantly accelerating the identification of promising, high-quality antibody leads.
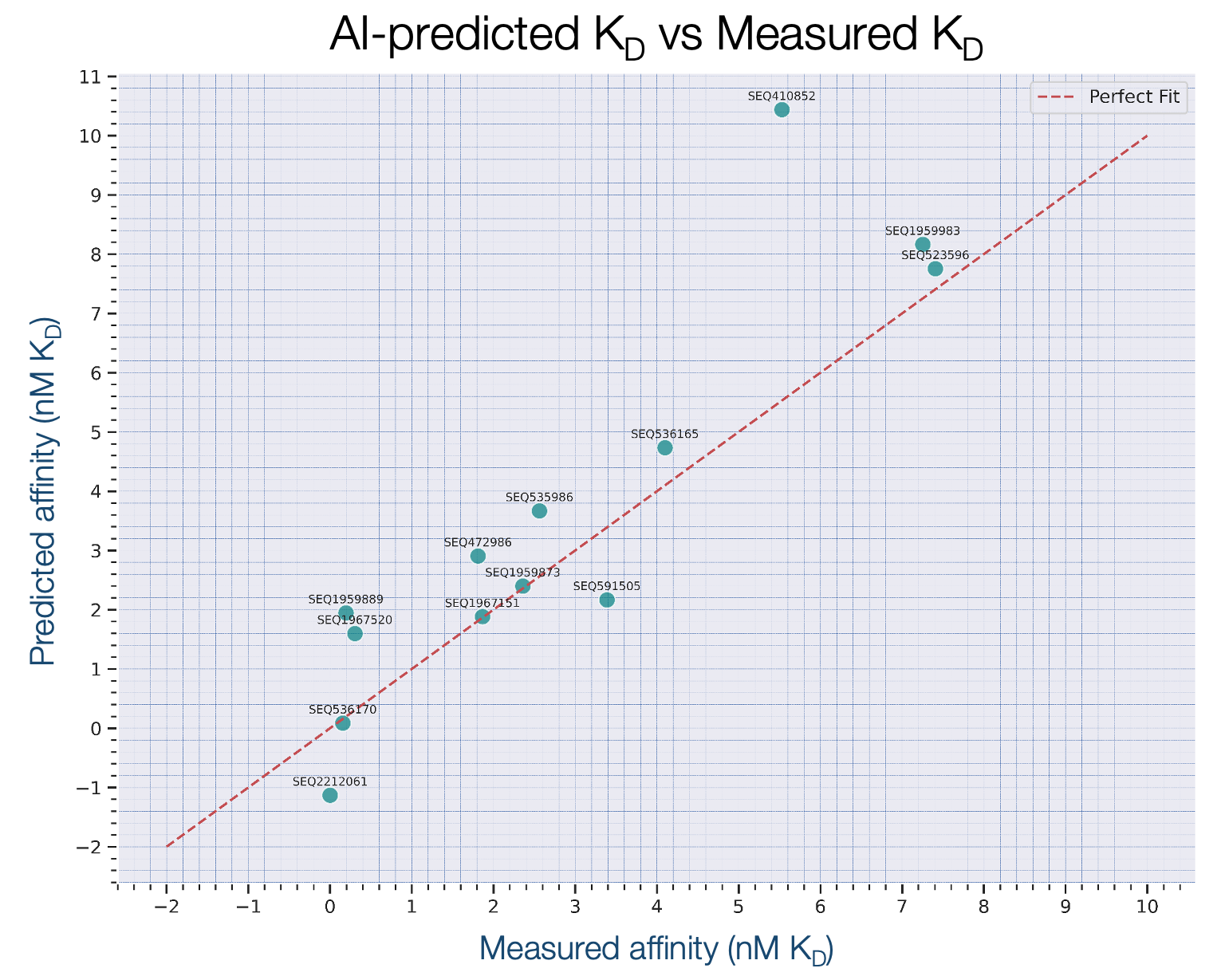
Result: Accurate prediction
We confirmed the high accuracy of our AI’s binding affinity predictions, demonstrating a strong correlation between its predicted KD values and actual experimental measurements. Leveraging this robust predictive power allows for effective candidate prioritization, thereby streamlining experimental validation and conserving valuable time and resources.
Result: Diverse epitopes
Our AI successfully designed antibodies targeting diverse epitopes across the SARS-CoV-2 RBD, a key finding subsequently confirmed through independent validation by Integral Molecular using their precise Shotgun Mutagenesis platform. This proven ability to generate candidates with broad epitope coverage significantly enhances the potential for discovering effective therapeutic antibodies possessing optimal functional properties.
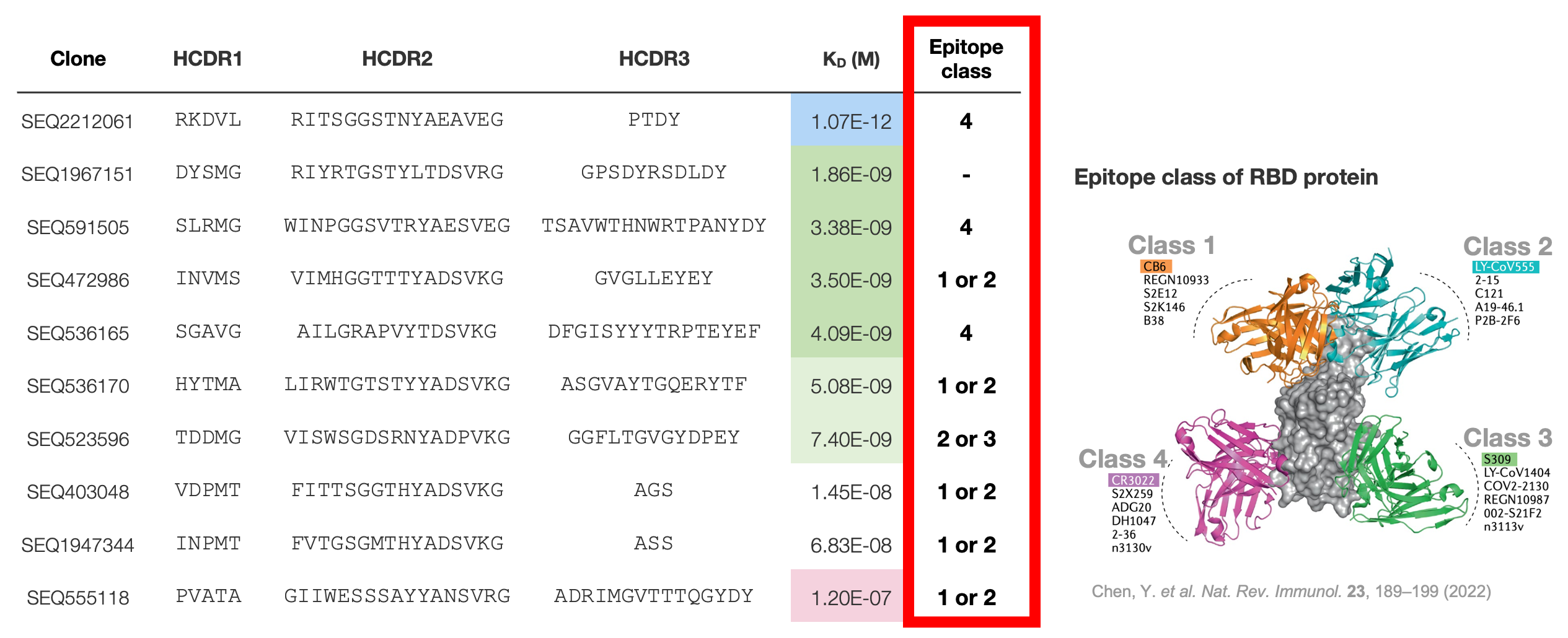
* Each KD values are measured via Octet.
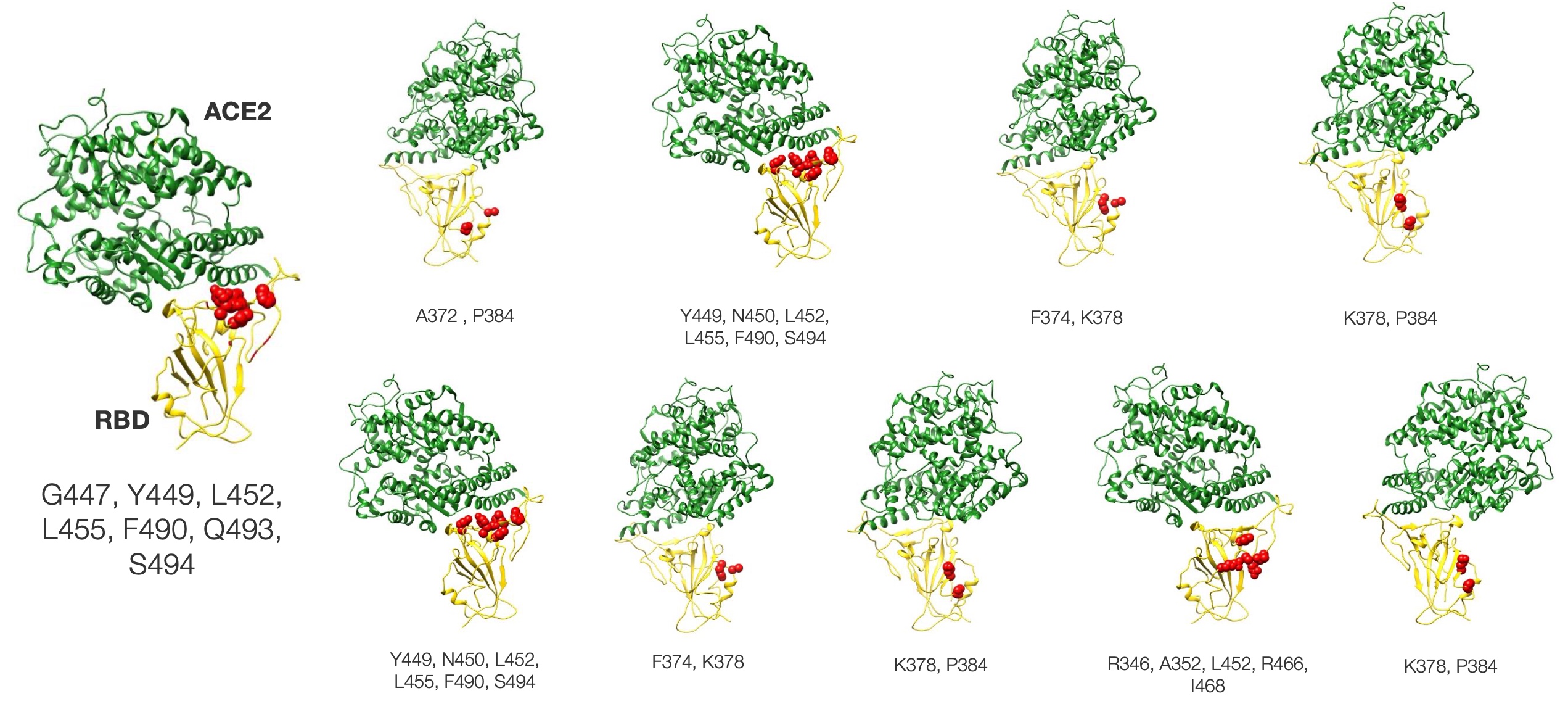
Data by Integral Molecular, Inc. Structure data from PDB (7KNB)
Result: de novo Discovery
MOLCURE’s generative AI designs entirely novel VHH antibodies de novo, achieving remarkable sequence diversity and impressive high affinities reaching the picomolar range, a significant feat for newly generated candidates. This powerful capability significantly expands the scope of antibody discovery, allowing exploration far beyond traditional library limitations to unlock novel therapeutic potential.